Text-to-SQL mit AI Agents: Effiziente Datenanalyse per Sprache
Wie lassen sich komplexe Datenbanken effizient auswerten – ganz ohne SQL-Kenntnisse? Unternehmen sitzen häufig auf großen Mengen strukturierter Daten, die in relationalen Datenbanken abgelegt sind: in einem Hotel etwa Buchungen, Gästeinformationen oder POS-Daten (Point of Sale). Die jeweiligen Fachabteilungen verfügen jedoch oft nicht über die nötigen SQL-Kenntnisse, um diese Daten gezielt abzufragen und für fundierte Entscheidungen zu nutzen.
Hier bietet Text-to-SQL mit AI-Agents einen vielversprechenden Ansatz: Nutzer stellen Fragen in natürlicher Sprache, der Agent übersetzt diese automatisch in passenden SQL-Code, führt sie auf der Datenbank aus und bereitet die Ergebnisse verständlich auf. Das Ziel ist klar: „Talk to your Data“, aber ohne tiefgehende Datenbankkenntnisse.

Trotz des theoretischen Potenzials von Text-to-SQL zeigt die Forschung jedoch verschiedene technische Hürden auf. Die zugrundeliegenden Large Language Models neigen zu Halluzinationen und das Datenbank-Schema muss korrekt erkannt und interpretiert werden. Bereits kleine Fehler, etwa ein falscher Join, ein falsch benanntes Attribut oder eine leicht abweichende Interpretation der Nutzerfrage, führen zu nicht ausführbaren oder inhaltlich falschen Ergebnissen. Besonders kritisch ist dabei, dass solche Fehler nicht immer sofort auffallen – vor allem, weil die Antwort der KI stets selbstbewusst und plausibel formuliert ist.
In diesem Beitrag zeigen wir am Beispiel einer Hotel-Datenbank, wie diesen Herausforderungen in der Praxis begegnet werden kann und welche Lösungsansätze sich bewährt haben – von robusten Workflow-Strukturen über Schema-Awareness bis hin zu Methoden wie Chain-of-Thought Prompting, Semantic Layers oder Execution-Guided Decoding.
n8n als Plattform für AI Agents
Für die Umsetzung setzen wir auf n8n, eine Low-Code-Workflow-Plattform, mit der sich komplexe Abläufe strukturiert und nachvollziehbar modellieren lassen. Externe APIs, Datenbanken und Large Language Models können nahtlos integriert werden. Ein zentraler Vorteil von n8n liegt dabei in der Modularität und Transparenz: Jeder Verarbeitungsschritt ist explizit abgebildet und auch ohne tiefes technisches Verständnis gut nachvollziehbar.
AI Agents übernehmen dabei selbstständig die Entscheidungslogik: Die KI analysiert eine Nutzeranfrage in natürlicher Sprache, gleicht die darin enthaltenen Anforderungen mit dem zugrundeliegenden Datenbank-Schema ab und übersetzt die Anfrage anschließend in eine SQL-Query. Diese wird mithilfe eines passenden Tools ausgeführt und das Ergebnis wird im Chat zurückgegeben. Die dafür notwendigen Reasoning-Schritte erfolgen implizit innerhalb des AI- Agents, ohne dass umfangreiche und explizite Steuerlogik im Code implementiert werden muss.
Für unsere Tests haben wir ein relationales Datenbankmodell für ein Hotel-POS-System erstellt. Dieses Modell bildet typische Strukturen wie Buchungen, Gästeinformationen, Bestellungen und Abrechnungen ab. Die Datenbank läuft zusammen mit unserer n8n-Instanz in einer Docker-Umgebung, sodass alle Komponenten reproduzierbar und isoliert betrieben werden können. Realistische, fest definierte Dummy-Daten ermöglichen die reproduzierbare Evaluation verschiedener Fragestellungen. Wir loggen Abfragen, Ergebnisse, Laufzeiten und Token-Verbrauch systematisch, um die Qualität und Effizienz verschiedener Ansätze zu analysieren.
Erster Ansatz: Ein Agent macht alles
Im ersten Ansatz übernimmt ein einzelner AI-Agent sämtliche Aufgaben: Er erhält die Nutzerfrage sowie das vollständige Datenbankschema als Ground Truth (Daten, die der AI-Agent als Referenz nutzt und als korrekt ansieht), generiert daraus eine SQL-Query, führt diese aus, interpretiert das Ergebnis und gibt die Antwort zurück.
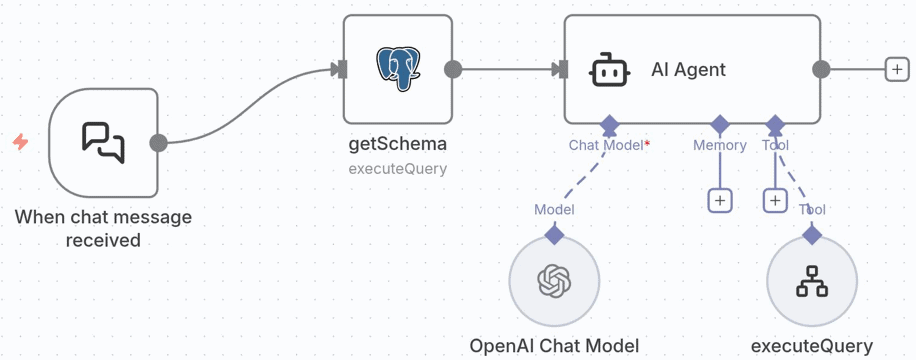
Dieser Ansatz ist naheliegend, da er konzeptionell einfach ist und mit minimalem Setup auskommt. In der Praxis zeigt sich jedoch schnell, dass diese Strategie an ihre Grenzen stößt. Typische Probleme sind:
- erfundene Spalten- oder Tabellennamen,
- fehlerhafte Joins,
- inkonsistente Umbenennung von existierenden Attributen,
- falsche Interpretationen der Nutzerfragen.
Iterative Verbesserungen des Text-to-SQL-Ansatzes
Ausgehend von dem vorgestellten naiven Ansatz haben wir den Workflow iterativ weiterentwickelt. Dabei standen zwei Ziele im Fokus: Die Sicherstellung syntaktisch wie semantisch korrekter Ergebnisse, bei möglichst vertretbarem Ressourcenverbrauch.
1. Prompt Engineering als erste Absicherung
Ein naheliegender erster Schritt ist gezieltes Prompt Engineering. Durch klar formulierte Regeln lassen sich viele triviale Fehler bereits im Vorfeld eliminieren. Dazu gehören unter anderem Vorgaben wie das Verbot, Tabellen oder Spalten umzubenennen oder das Erfinden nicht existierender Attribute.
Empirisch reduziert diese Veränderung einfache Halluzinationen. Gleichzeitig steigt die Anzahl der Input-Tokens leicht, da das Prompt umfangreicher wird. Komplexe Fragestellungen bleiben jedoch weiterhin fehleranfällig.
2. Vergleich verschiedener LLMs für Text-to-SQL
Nicht jedes Large Language Model eignet sich gleich gut für die Generierung von SQL (vgl. bestehende Literatur und öffentliche Benchmarks, u.a. Tinybird LLM Benchmark und Aimultiple Text-to-SQL). Entsprechend haben wir unterschiedliche OpenAI-Modelle im identischen 1-Agenten-Setup miteinander verglichen.
Auch in unseren Experimenten (siehe unten) zeigten sich messbare, wenn auch moderate Unterschiede in der Performance. Insbesondere o4-mini, gpt-5-nano und gpt-4.1 lieferten gute Ergebnisse. Die Wahl des Modells ist damit ein relevanter, aber nicht allein entscheidender Faktor für die Gesamtqualität.
3. Kontextanreicherung des Datenbankschemas
Ein zentrales Problem vieler Text-to-SQL-Ansätze ist fehlende Schema-Semantik. Reine Tabellen- oder Spaltennamen liefern oft nicht genügend Kontext, um die Bedeutung der Daten korrekt zu erfassen.
Um dem entgegenzuwirken, haben wir das Datenbankschema semantisch angereichert: Tabellen und Attribute sind mit zusätzlichen Beschreibungen und Kommentaren versehen, wie beispielsweise gültige Werte bei Zahlenwerten oder Enums. Dadurch erhält der AI-Agent ein besseres Verständnis der Bedeutung einzelner Entitäten und Relationen. Der Nachteil: Mit wachsendem Kontext steigt der Token-Verbrauch im Input des AI-Agents, was die Effizienz etwas verringert.
4. Chain-of-Thought Prompting
Ein fortgeschrittener Ansatz zur Qualitätssteigerung ist Chain-of-Thought (CoT) Prompting. Die Grundidee besteht darin, das Modell zu zwingen, seine Entscheidungsfindung in nachvollziehbare, logische Zwischenschritte zu gliedern. Theoretisch lassen sich so komplexe Aufgaben robuster lösen und Fehlerquellen gezielter analysieren.
Zur Einordnung unterscheiden wir im Folgenden drei Varianten: Ohne Chain-of-Thought, bei der das Modell lediglich das Endergebnis erzeugt; implizites Chain-of-Thought, bei dem ein einzelner Agent mehrere notwendige Zwischenschritte intern nacheinander ausführt; sowie explizites Chain-of-Thought, wobei mehrere hintereinandergeschaltete Agenten jeweils einen klar abgegrenzten Arbeitsschritt übernehmen. Diese drei Varianten sind an der Analogie eines Kochrezepts illustriert:
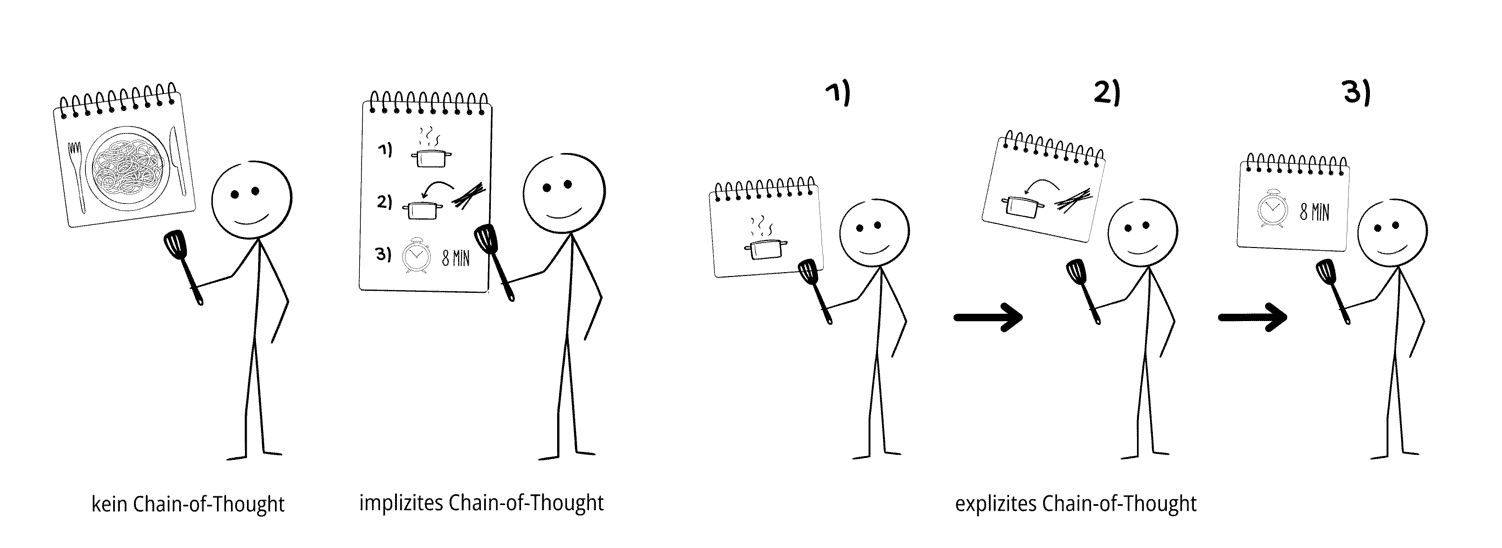
Unsere implizite Variante von Chain-of-Thought wurde direkt im Systemprompt umgesetzt: Der Agent erhält schrittweise Arbeitsanweisungen und muss seine Zwischenergebnisse am Ende ausgeben. Diese Lösung ist leichtgewichtig und schnell, führte jedoch nicht konsistent zu besseren Ergebnissen.
Deutlich robuster zeigte sich unsere explizite Variante mit mehreren LLM-Bausteinen. Der Workflow wurde in klar getrennte Schritte, realisiert durch einzelne AI-Agenten, aufgeteilt:
- Analyse der Nutzerfrage
- Identifikation relevanter Tabellen, Attribute, Bedingungen und Join-Pfade
- SQL-Generierung
- Validierung
- ggf. iterative Korrektur (bis die Validierung erfolgreich ist)
Alternativ wurden Schritte 1–3 sowie 4–5 zu jeweils einem Agenten zusammengefasst, um den Overhead zu reduzieren. Die Qualität der Ergebnisse stieg in beiden Fällen spürbar, allerdings auf Kosten eines deutlich höheren Token-Verbrauchs, da insbesondere die Kontextinformationen mehrfach als Input benötigt werden. Feinheiten in der Interpretation der Nutzerfrage bleiben jedoch weiterhin eine Herausforderung.
5.1. Mehr Kontext durch vollständigen Semantic Layer
Um die semantische Korrektheit der SQL-Generierung weiter zu erhöhen, wurde das Datenbankschema um einen Semantic Layer erweitert. Dieser geht bewusst über die reine Kommentierung einzelner Tabellen und Attribute hinaus und modelliert zusätzlich fachliche Konzepte, Metriken, sowie die Beziehungen zwischen Entitäten. Ziel ist es, implizite Geschäftslogik für den AI-Agenten explizit verfügbar zu machen.
Im Hotelkontext können so beispielsweise abgeleitete Konzepte wie “Frühstücksgäste” definiert werden, etwa als Anzahl der Gäste an einem bestimmten Tag, deren Buchung ein Frühstück inkludiert. Viele dieser Konzepte ergeben sich erst aus der Kombination mehrerer Tabellen oder Filterbedingungen und sind somit neu im Semantic Layer. Damit fungiert der Semantic Layer als Brücke zwischen natürlicher Sprache und der formalen Struktur der Datenbank.
Der Vorteil eines Semantic Layers: Der AI-Agent erhält ein deutlich tieferes Verständnis der Bedeutung einzelner Entitäten und Relationen und wird mit branchenspezifischem Vokabular vertraut gemacht, was zu präziseren SQL-Queries und Verständnis der Nutzerfragen führt. Allerdings erhöht ein vollständiger Semantic Layer den Token-Verbrauch stark, da sämtliche Kontextinformationen für jeden AI-Agent als Input bereitgestellt werden müssen.
In Kombination mit dem Chain-of-Thought-Ansatz lässt sich der Token-Verbrauch teilweise reduzieren: Sobald die relevanten Tabellen für eine Anfrage identifiziert wurden, kann der Semantic Layer gezielt gefiltert werden. So erhalten nur die ersten Agenten die vollständigen Kontextinformationen, während spätere Schritte auf einen kleineren, relevanten Ausschnitt zugreifen.
5.2 Effizienter Zugriff mit Vektor-Datenbanken
Als Alternative zur Übergabe des gesamten Semantic Layers als JSON- oder Textinput wurde ein vektorbasiertes Retrieval getestet: Jede Entität, jedes Attribut und jedes fachliche Konzept werden jeweils in eine numerische Repräsentation (“Vektor”) überführt und als separater Eintrag in einer Vektor-Datenbank abgelegt. Diese Repräsentationen erlauben es, Inhalte nicht nur anhand exakter Begriffe, sondern anhand ihrer semantischen Ähnlichkeit zu vergleichen. Der Zugriff erfolgt, indem ein Text eingegeben wird (z.B. “Zimmerkategorien von Hotel mit ID 1”), welcher ebenfalls vektorisiert und anschließend mit den in der Datenbank gespeicherten Vektoren verglichen wird. Zurückgegeben werden die Einträge der Datenbank, die in der Vektor-Darstellung am nächsten zu dem Such-Vektor sind (hier z.B. Informationen zu Tabellen Hotel und Room sowie das Attribut room_category).
Dadurch kann der AI-Agent nun kontextabhängig gezielt nach den relevantesten Einträgen suchen und bekommt statt dem vollständigen Semantic Layer nur die Ausschnitte präsentiert, die inhaltlich zur jeweiligen Nutzerfrage passen und als Kontext für die weitere Verarbeitung benötigt werden.
Dieser Ansatz reduziert die Anzahl der Input-Tokens deutlich und skaliert besser bei größeren und komplexeren Schemata. Gleichzeitig besteht das Risiko, dass relevante Informationen nicht vollständig berücksichtigt werden, wenn sie nicht aktiv vom Agenten abgefragt werden. Effizienz und Vollständigkeit müssen hier daher sorgfältig gegeneinander abgewogen werden.
6. Execution-Guided Decoding
Zur Sicherstellung syntaktisch korrekter SQL-Queries kam Execution-Guided Decoding zum Einsatz. Dabei wird die (vollständige oder teilweise) Query bereits während der Generierung und/oder Validierung testweise ausgeführt. Auftretende Fehlermeldungen oder unplausible Ergebnisse können so direkt in eine iterative Verbesserung einfließen.
Dieser Ansatz reduziert die Anzahl nicht ausführbarer Queries erheblich. Logisch falsche, aber syntaktisch korrekte Anfragen lassen sich dadurch jedoch nicht automatisch erkennen – Execution-Guided Decoding stellt somit keine semantische Absicherung dar, sondern ergänzt bestehende Maßnahmen auf syntaktischer Ebene.
Empirischer Vergleich unserer Ansätze
Die vorgestellten Erweiterungen des Text-to-SQL-Workflows wurden systematisch evaluiert. Ziel war es, die Auswirkungen einzelner Maßnahmen auf Ergebnisqualität, Robustheit und Effizienz vergleichbar zu machen. Die folgenden Ergebnisse fassen die zentralen Beobachtungen entlang der iterativen Entwicklungsschritte zusammen.
Modellwahl: relevant, aber nicht ausreichend
Der Vergleich verschiedener Large Language Models im einfachen 1-Agenten-Setup zeigt, dass die Modellwahl einen messbaren Einfluss auf die Qualität der SQL-Generierung hat:
| gpt-4.1 | gpt-4.1 (alt) | gpt-5-nano | gpt-5-nano (alt) | 04 mini | 04 mini (alt) | |
|---|---|---|---|---|---|---|
| Mittel | 66,67 % | 80 % | 100 % | 70 % | 60 % | 80 % |
| Schwierig | 80 % | 25 % | 45 % | 40 % | 45 % | 35 % |
| Alle | 78,33 % | 43,44 % | 63,33 % | 50 % | 50 % | 50 % |
(jeweils 2 stärkste Models vor und nach Schema-Anreicherung im Vorher-Nachher-Vergleich)
Insbesondere bei komplexen Fragestellungen verbessert sich die Trefferquote signifikant. Dieser Effekt ist modellübergreifend sichtbar und bestätigt die zentrale Bedeutung von Schema-Awareness für Text-to-SQL-Anwendungen. Auf dieser Basis wurden alle weiteren Experimente durchgeführt.
Chain-of-Thought: Struktur schlägt Komplexität
Explizite Chain-of-Thought-Workflows erhöhen die Robustheit der Ergebnisse:
| 2 Agenten (VDB) |
1 Agent (JSON) |
5 Agenten (VDB) |
2 Agenten (JSON) |
|
|---|---|---|---|---|
| Mittel | 90 % | 80 % | 66,76 % | 50 % |
| Schwierig | 65 % | 68,33 % | 60 % | 50 % |
| Alle | 73,33 % | 71,76 % | 61,54 % | 50 % |
(Setups aus einem oder mehreren Agenten, Schema als JSON oder Vektor-DB bereitgestellt)
Dabei zeigt sich jedoch kein direkter Zusammenhang zwischen Anzahl der Agenten und Qualität. Ein schlankes 2-Agenten-Setup erreicht vergleichbare oder bessere Ergebnisse als komplexere Varianten, bei deutlich geringerem Ressourcenverbrauch. Mehr Agenten bedeuten somit nicht automatisch bessere Resultate.
Der Einsatz von Vektor-Datenbanken zur kontextabhängigen Informationsbeschaffung verbessert die Ergebnisqualität im 2-Agenten-Setup. Trotz identischem Inhaltsumfang performt der aktive Abruf relevanter Informationen besser als die vollständige Übergabe des Kontexts. Der erhoffte Rückgang des Token-Verbrauchs zeigt sich in dieser Konfiguration jedoch nur eingeschränkt:
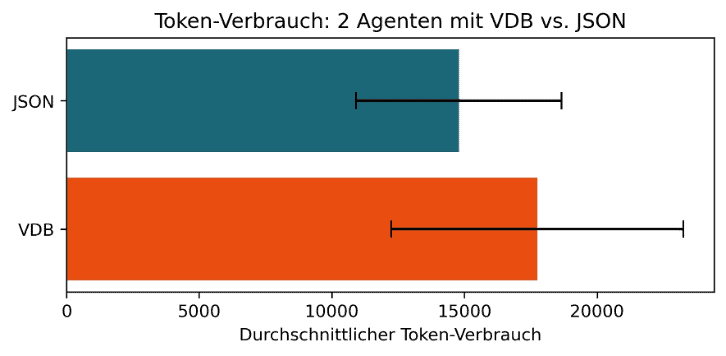
Execution-Guided Decoding als technische Absicherung
Execution-Guided Decoding reduziert zuverlässig syntaktische Fehler und nicht ausführbare SQL-Queries, hier im direkten Vergleich als 2-Agenten-Setup:
| 2 Agenten (zweiter mit EDG) | 2 Agenten (beide ohne EDG) | |
|---|---|---|
| Mittel | 50 % | 50 % |
| Schwierig | 65 % | 50 % |
| Alle | 60 % | 50 % |
(2 Agenten, wobei der letzte einmal EGD verwendet, einmal nicht) Der Einfluss auf die Korrektheit bleibt begrenzt, dennoch erhöht der Ansatz die technische Stabilität des Gesamtsystems und eignet sich als ergänzende Absicherung.
Fazit: Text-to-SQL mit AI Agents praxisnah gedacht
Text-to-SQL mit AI-Agents eröffnet Unternehmen neue Möglichkeiten ihre Daten effizient und niederschwellig zu nutzen. Unsere Experimente zeigen jedoch deutlich: Ein naiver „One-Agent-does-it-all“-Ansatz reicht für produktive Szenarien nicht aus. Erst durch gezielte Erweiterungen wie Schema-Awareness, strukturierte Chain-of-Thought-Workflows, kontextabhängigen Zugriff über Vektor-Datenbanken und technische Absicherungen wie Execution-Guided Decoding lassen sich robuste und verlässliche Ergebnisse erzielen.
Dabei wird deutlich, dass jeder Qualitätsschritt seinen Preis hat: Mehr Kontext, zusätzliche Agenten oder erweiterte Validierungen verbessern die Trefferquote, erhöhen jedoch auch den Input-Token-Verbrauch und die Laufzeit. Der zentrale Erfolgsfaktor liegt daher nicht in maximaler Komplexität, sondern in einer bewussten Abwägung zwischen Qualität und Effizienz – insbesondere schlanke, gut strukturierte Multi-Agenten-Setups erweisen sich oft als Sweet Spot.
Darüber hinaus bleibt Text-to-SQL ein dynamisches Entwicklungsfeld mit weiterem Optimierungspotenzial. Dynamische Kontext-Injektion, bei der nur situationsabhängig relevanter Kontext bereitgestellt wird, verspricht zusätzliche Effizienzgewinne. Eine vollständige Umsetzung des Workflows außerhalb von n8n, zum Beispiel in einer Python-basierten Architektur, kann Latenzen weiter reduzieren und mehr Kontrolle über Ausführung und Caching bieten. Agentische Frameworks wie LangGraph eröffnen darüber hinaus neue Möglichkeiten, komplexe Entscheidungslogiken explizit zu modellieren und die Stabilität des Systems zu erhöhen.
Für Unternehmen bedeutet das: Text-to-SQL ist kein Plug-and-Play-Feature, sondern ein strategisches Analytics-Thema. Richtig umgesetzt ermöglichen AI-Agents jedoch genau das, was moderne Datenorganisationen brauchen – einen intuitiven, skalierbaren und zukunftssicheren Zugang zu ihren Daten.
👉 Sie möchten Text-to-SQL und AI Agents sinnvoll in Ihre Analytics-Landschaft integrieren?
Vereinbaren Sie jetzt ein unverbindliches Beratungsgespräch mit uns – wir unterstützen Sie von der Konzeption bis zum produktiven Einsatz.
Feedback
Wir freuen uns über Feedback und weiteren Austausch zu AI Agents.