Natürlich ist die Freude groß, wenn die eigene Webseite zunehmend stark besucht wird und man dadurch (vermeintlich) mehr Reichweite bekommt. Wenn sich der neu gewonnene Traffic jedoch als nicht menschlich, sondern als sogenannter Bot Traffic herausstellt, sieht die Welt plötzlich ganz anders aus …
Doch was ist Bot Traffic eigentlich genau, wie kann ich ihn in meinen Analytics Daten identifizieren und wie gehe ich mit dem Wissen darum um? Damit ihr zukünftig einen kühlen Kopf bewahren könnt, liefern wir euch in diesem Blogpost wichtige Best Practice Tipps & Tricks rund um das Thema Bot Traffic. 🤖
Was ist Bot Traffic eigentlich genau?
Als Bot bezeichnet man Skripte bzw. Programme, die automatisch und wiederholt Aufgaben über ein Netzwerk ausführen und dabei einen Menschen imitieren oder ersetzen.
So nutzen mittlerweile viele Unternehmen „Chatbots“ im Customer Care Bereich, aber auch sogenannte „Web-Crawler“ und „Scraper“ sind aus unserem Alltag nicht mehr wegzudenken. Ohne ihr ständiges Durchforsten des Internets nach den Preisen verschiedener Anbieter oder nach aktuellen Nachrichten, würden Vergleichsportale, Suchmaschinen oder News-Ticker nicht so funktionieren wie sie es tun. Diese Art bzw. Nutzung von Bots wird auch als „gute“ Bots bezeichnet.
Und wo es Licht gibt, da fällt in der Regel auch Schatten, denn Bots können selbstverständlich auch für andere Zwecke missbraucht werden. Dann sprechen wir von den sogenannten „bösen“ Bots. In diesem Fall werden sie für unterschiedliche Arten des Spammings (Def.: wiederholtes, massenhaftes Senden von Nachrichten) genutzt. Hierbei reicht das Spektrum von (Spam)-E-Mails bis massenhaften Serveranfragen, besser bekannt als DDoS (Distributed Denial of Service)-Attacken, die ganze Webseiten für einen bestimmten Zeitraum unerreichbar machen. Je nach Einsatzgebiet, können Bots ebenso genutzt werden, um Online-Umfragen oder Social Media Inhalte zu manipulieren (z.B. Up-/Down Votes, Reichweitengenerierung, etc.).
Da wir jetzt wissen, was Bot-Traffic sein kann, stellt sich die Frage, wie ich mit ihm umgehe und ihn in meinen Analytics Daten eindeutig identifizieren kann. Generell wird davon ausgegangen, dass knapp unter 50% des gesamten Internetverkehrs (Internet-Traffics) durch Bots generiert wird und davon nur etwa 17% von „guten“ Bots (s. Abbildung). Wenn man ein wenig aufrundet, kann also festgehalten werden, dass ca. 1/3 des gesamten Internetverkehrs von „schlechten“ Bots erzeugt wird.
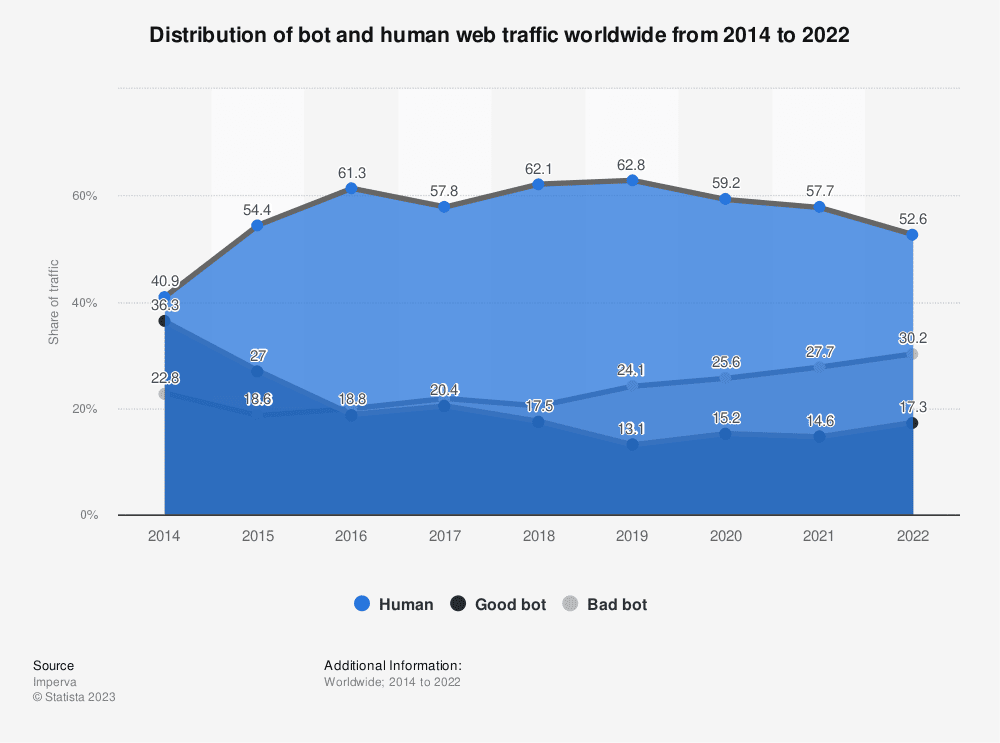
Aufteilung des Internetverkehrs nach Quelle, Statista*
Im Analytics Kontext sehen wir in der Regel nur den Traffic, der es durch mindestens einen Bot-Filter geschafft hat. Denn alle gängigen Analytics Tools haben einen Bot-Filter integriert. Dieser ist mal mehr und mal weniger bis gar nicht individualisierbar (einstellbar) und mal mehr oder weniger erfolgreich in seinem Job.
Man kann aber auch auf anderem Wege dafür sorgen, dass man keinen Bot Traffic mehr in seinen Daten hat: Man identifiziert ihn schon direkt auf seiner Webseite und markiert bzw. blockiert ihn daraufhin. Diese Lösungen werden von Anbietern wie z.B. Akamai und Cloudflare angeboten. Sie überwachen, als zwischengeschaltete Instanz, den Web-Traffic auf den Webseiten. Hierbei ist es wichtig, sich an die spezifischen Anweisungen der Anbieter zu halten. Dazu wird meist ein Code-Snippet auf der Webseite implementiert oder der Server entsprechend konfiguriert.
Wenn es der Bot Traffic trotz vorheriger Filter in eure Daten schafft, bleibt nur noch die Möglichkeit, selbst aktiv zu werden. Hierbei gilt es zunächst, Anomalien, also Abweichungen, zu erkennen und diese dann zu benennen. Wenn es einfache, „dumme“ Bots sind, fällt das Identifizieren sehr leicht. Sie haben meist die gleiche Geo-Location als Ursprung, seltsame, nicht handelsübliche Bildschirmauflösungen, veraltete Browser Versionen, den gleichen User Agent oder seltsame Service Provider bzw. Netzwerk Domains. Schwieriger wird es dann, wenn die Bots etwas „schlauer“ sind und auch mehrere Seitenaufrufe in einer Session generieren, sich nicht sofort in menschenunmöglicher Geschwindigkeit über bzw. zur nächsten Seite bewegen oder die Cookies nicht sofort löschen und ein sogenannter „wiederkehrender Nutzer“ sind.
Hierzu schauen wir in die Analytics Daten und versuchen aus den entsprechenden Mustern abzuleiten. Anhand dieser Muster können dann wiederum bestimmte Eigenschaften definiert werden, über welche dann wiederum Traffic, auf den diese Eigenschaften zutreffen, ausgeschlossen werden kann.
Wenn wir es mit einem nicht allzu intelligenten Bot zu tun haben, kann z. B. ein Muster die bereits erwähnte Geo-Location sein, über die dann mit einem Segment oder Filter der Traffic ausgeschlossen werden kann. Eine weitere Möglichkeit ist, aus verschiedenen Dimensionen und Metriken eine Art Ranking zu erstellen, darüber anschließend den User Agent zu ermitteln und dann diesen expliziten User Agent auszuschließen. Diese Dimensionen und Metriken können u.a. folgende sein:
| Dimensionen | Metriken |
|---|---|
| User Agent | Average Time on Site |
| Browser ID / Version | Instances |
| Location/Country/City | Visits |
| Device Type | Page Views |
| Marketing Channel | Bounce Rate |
| CMP/Consent | Orders/Purchases |
| Display Größe | Cart Additions |
| Netzwerk Domain | Revenue |
| Referrer | Page View per Visit or per Session |
| Operating System | First Time Visits |
| E-Commerce Conversion Rate | |
| Search Results View |
Doch was genau ist eigentlich der „User–Agent“ über den ich diese Bots dann ausschließen kann? Der User Agent ist eine Kennung, mit der sich der Browser des Nutzers beim Server der Webseite meldet. Diese Kennung setzt sich u. a. aus Werten wie der Plattform (Betriebssystem), Rendering Engine (System, das zur Darstellung der Inhalte genutzt wird) und Browser (Name und Version) zusammen.
Wenn bereits alles versucht wurde, es aber immer noch den Verdacht gibt, dass die Daten verunreinigt sind, können auch Ereignisse oder Schritte von der Webseite oder aus dem E-Commerce-Funnel für Filter oder Segmente herangezogen werden, die tatsächlich nur Menschen bewältigen können. So kann man z.B. den Kaufabschluss, eine Nutzeraccount-Anmeldung oder Newsletter-Anmeldung nutzen, um rein menschliche Interaktionen zu markieren und somit auch den Traffic der menschlichen Nutzer. Dieser Schritt ist relativ „radikal“. Daher würden wir empfehlen, mit diesen Informationen lediglich ein Segment zu erstellen und nicht gleich den anderen Traffic mittels Filter auszuschließen. Eine weitere Möglichkeit Bots zu identifizieren, wäre ein sogenannter Honeypot, sprich eine Falle, auszulegen. Das können zum Beispiel für den Nutzer unsichtbare Links oder Buttons sein, die von Bots geklickt werden. Hierbei braucht man jedoch die Unterstützung und Erlaubnis der Seitenbetreiber. Weshalb wir Consultants es zunächst mit ersterer Methode versuchen. Wie man den identifizierten Bot Traffic nachträglich in Adobe und Google Analytics ausschließt, was zu beachten ist und was die Vor- und Nachteile dieser Methoden sind, zeigen wir euch in unserem Folge-Blogbeitrag zum Thema Bot Traffic. Stay tuned! 🤖
Fazit
Der Umgang mit Bot Traffic in Analytics Tools ist von entscheidender Bedeutung, um genaue und zuverlässige Daten für eure Webanalysen zu erhalten. Durch die Identifizierung und den Ausschluss von Bot Traffic könnt ihr sicherstellen, dass eure Entscheidungen auf fundierten Informationen basieren.
Ihr beobachtet anomales Verhalten auf eurer Website und vermutet, dass es sich um Bot Traffic handeln könnte?
Unsere Digital Analytics Experten helfen euch bei der eindeutigen Identifizierung, überprüfen eure Analytics-Einstellungen und aktualisieren sie kontinuierlich, um mit den sich ständig ändernden Bot-Taktiken Schritt zu halten. Sprecht uns gerne direkt an!
Feedback
Wir freuen uns über Feedback und weiteren Austausch zu Bot Traffic in Analytics Tools und Best Practices.