Was ist eine Clusteranalyse – Ein kleiner Einblick
Die Arbeit mit Datenmengen ist im Bereich Digital Analytics nicht wegzudenken. Neben dem Erfassen, Aufbereiten und Reporten sind auch vor allem spezifische Analysen der Daten ein wichtiger Bestandteil dieser Arbeit. Heute wollen wir ein ganz bestimmtes statistisches Verfahren vorstellen, die Clusteranalyse.
Das Ziel einer Clusteranalyse liegt darin, in einer Datenmenge Ähnlichkeiten und/oder Unterschiede festzustellen und auf dieser Grundlage die Objekte in Klassen (bzw. Cluster) einzuteilen. Dabei können die Verfahren die Datenmenge in eine vorher vorgegebene Anzahl von Klassen unterteilen oder auch komplett selbstständig Klassen identifizieren. Die in den Daten vorliegende Klasseneinteilung, welche die Analyse erkennen soll, nennt man dabei die natürliche Struktur.
Zunächst klingt es nicht nach einer Herausforderung, aber gerade bei sehr großen Datenmengen oder bei Daten mit mehr als drei Merkmalen ist mit dem bloßen Auge das Auffinden von natürlichen Strukturen nicht mehr möglich. Insbesondere Daten im dreidimensionalen Raum kann man schlicht und einfach leicht erfassen und benötigen eine besondere Visualisierung.
Was bringt eine Klassifikation von Daten bei der Clusteranalyse?
Hypothesen, welche man im Voraus auf Grundlagen der Datenmenge getroffen hat, kann man durch die Analyse mathematisch stützen oder verwerfen. Mit Hilfe der gefundenen Klassen kann man dann neue Aussagen über die Verteilung der Datenobjekte machen oder Vermutungen bestätigen. Oft erbringen Analysen auf den bereits klassifizierten Daten tiefere Erkenntnisse, als wenn sie auf der gesamten Datenmenge durchgeführt worden wären.
An einem Beispiel aus dem Alltag wird der Nutzen klarer. Stehen wir morgens vor dem Kleiderschrank können wir uns meisten mit wenig Handgriffen ein in den meisten Fällen tragbares Outfit zusammenstellen. Dies ist aber nur möglich, wenn wir unsere Klamotten vorher nach bestimmten Kategorien sortiert haben. Viele Menschen versuchen dabei zum Beispiel Hosen, Pullover, Socken etc. auf einem Stapel anzuordnen. Andere gehen sogar soweit die Kleider nach Farbe oder Jahreszeit zu ordnen. Je größer die Anzahl an Kleidungstücken dabei ist, umso mehr Sinn macht dabei eine feinere Sortierung. Denn die wenigstens haben wahrscheinlich Lust jeden Morgen aus einem riesigen Haufen Klamotten ein Paar passender Socken zu suchen.
Es gibt jedoch auch Sortierungen, welche weniger sinnvoll sind, beispielweise nach Gewicht und Preis. Ebenso gibt es bei Clusteranalysen mehr und weniger erkenntnisreiche Ergebnisse.
Dieses Prinzip lässt sich leicht auch auf technische Fälle anwenden. Angenommen es existiert eine Webseite, welche Waren aus verschiedenen Kategorien zum Verkauf anbietet. Interessant wäre es zu wissen, ob Besucher der Seite aufgrund ihres Verhaltens in verschiedene Käufer-Typen eingeordnet werden können. Typische Fragen wären hierbei, welches Verhalten bei Besuchern eher zu einem Kaufabschluss oder im Vergleich zu einem höheren Umsatz führt. Oder aber, ob bestimmte Produkte bevorzugt im Einkaufswagen landen, bevor es zu einem Kaufabschluss kommt. Diese Fragestellungen kann man durch eine Clusteranalyse z.B. auf Basis der Seitenaufrufe in den einzelnen Produktkategorien und des Umsatzes pro Kunde beantworten.
Wie funktioniert die Mathematik dahinter?
Mathematisch werden zwei Bedingungen bei der Clusteranalyse an die entstehenden Klassen gestellt. Zum einen sollen Objekte aus gleichen Klassen untereinander ähnlich sein und andererseits sollen Objekte aus verschiedenen Clustern unähnlich zueinander sein. Dies hört sich zunächst trivial an, benötigt jedoch eine genaue mathematische Definition. Nach einer erfolgreichen Clusteranalyse sollte idealerweise jede gefundene Gruppe ganz bestimmte Strukturen aufweisen, sodass ein Cluster durch seine Eigenschaften oder eventuell durch die Wahl eines Repräsentanten direkt Aufschluss über seine enthaltenen Objekte gibt und eine mögliche Interpretation zulässt. Klassen mit wenigen Objekten kann man hierbei meist als Ausreißer-Klasse identifizieren. In jedem Fall sollte die Analyse eine leichter überschaubare und übersichtlichere Struktur vorweisen.
Es gibt verschiedene statistische Herangehensweisen für eine Klassifizierung der Daten. Die Auswahl des Verfahrens hängt dabei von der Beschaffenheit der Daten und in hohem Maße von dem Ziel, welches erreicht werden soll, ab. Die verschiedenen Verfahren unterscheiden sich primär durch den mathematischen Algorithmus, welcher zur Analyse verwendet wird. Es existieren auch verschiedenste Möglichkeiten die Ähnlichkeit bzw. Unähnlichkeit von zwei Objekten bzw. zwei Klassen zu beschreiben. Ein erfahrener Analyst hat in vielen Fällen sofort ein Gespür dafür, welche Berechnungen sich für die vorliegenden Beobachtungen besonders eignen. Vor der Auswahl ist aber eine genaue Voruntersuchung und eventuelle Aufbereitung der Daten unbedingt notwendig. Andernfalls können Ergebnisse entstehen, die gar keine oder eine falsche Interpretation zulassen.
Die Herausforderung „Big Data“
Typischerweise sind die Datenmengen, die in digitalen Bereichen (z.B. Website Tracking, App Tracking, etc.) erhoben werden, sehr groß. Daher sind eine schnelle Rechenlaufzeit und sparsame Speicherverwaltung grundlegende Anforderungen an jedes statistische Verfahren. Viele klassische clusteranalytische Verfahren, welche zwar gut darin sind Klassenstrukturen aufzudecken, scheiden daher schon von vornherein aus. Die Durchführung solcher Verfahren würde bei Umfängen, wie sie im Big Data Bereich vorkommen, meist mehrere Tage oder Wochen beanspruchen. Wir wollen daher zwei spezielle Verfahren vorstellen. Zum einen den verbreiteten k-Means Algorithmus und zum anderen den weniger bekannteren BIRCH Algorithmus. Hierbei werden wir ein kleines Stückchen tiefer in die Mathematik hinter den Algorithmen steigen, um die Unterschiede und Vor- und Nachteile herauszuarbeiten. Mit Hilfe dieser beiden Verfahren, können bereits viele Erkenntnisse über die natürliche Struktur innerhalb der Daten gewonnen werden.
Als Beispieldatensatz betrachten wir fiktiven Daten mit 1 Mio. Objekten, die je drei Merkmale aufweisen (siehe Abb. 1). Wir können die Daten also in einem dreidimensionalen Koordinatensystem visualisieren.
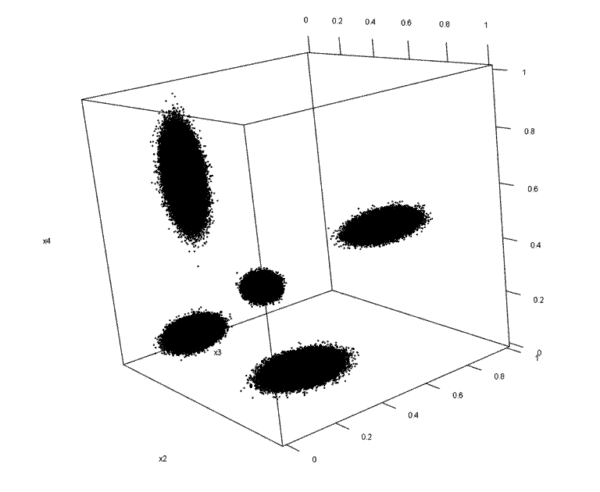
Abbildung 1: Plot fiktiver Datensatz
In diesem Beispiel kann die natürliche Struktur der Daten durch bloßes Hinsehen erkannt werden. Die Objekte lassen sich in fünf verschiedene „Anhäufungen“ oder „Blasen“ einteilen. Trotzdem ist nicht bekannt welches einzelne Objekt im Datensatz welcher der fünf Klassen zugeordnet werden kann. Bei 1 Mio. Objekten ist die händische Zuteilung auch schon nicht mehr in verhältnismäßiger Zeit möglich. Daher werden wir die Zuteilung über die Algorithmen vornehmen. In der Realität ist jedoch die Trennung zwischen den Klassen meist wesentlich weniger eindeutig.
Im zweiten Teil dieses Artikels werden wir die zwei Verfahren vorstellen, welche das Problem mit unterschiedlichen Herangehensweisen lösen. Dabei werden wir sehen, dass je nach Beschaffenheit der Daten, beide Verfahren mal besser und mal schlechter Ergebnisse liefern und im schlimmsten Fall kann auch eine völlig ungeeignete Klassifizierung berechnet werden kann.
Die Fortsetzung finden Sie hier: www.e-dynamics.de/blog/clusteranalyse-teil2