Effizientes Datenmanagement mit BigQuery
In unserer heutigen digitalen Ära generieren Unternehmen und Organisationen enorme Mengen an Daten. Um diesen Datenberg zu bewältigen und wertvolle Erkenntnisse zu gewinnen, benötigen sie leistungsstarke Datenverarbeitungstools. BigQuery, das Data Warehouse von Google Cloud, ist eine solche Plattform, die fortschrittliche Funktionen zur Verarbeitung und Analyse von großen Datenmengen bietet. Eine besonders nützliche Funktion von BigQuery sind die eventbasierten oder zeitgesteuerten geplanten Abfragen („Scheduled Queries“).
In diesem Blogbeitrag werden wir uns mit dieser Funktion anhand eines Use Cases in unserem Projektumfeld genauer beschäftigen, Grenzen aufzeigen und unseren eigenen Lösungsansatz für eventbasierte Abfragen in BigQuery vorstellen.
Was sind „Event Based Scheduled Queries“ eigentlich?
„Scheduled Queries“ ermöglichen es den Benutzern grundsätzlich Abfragen auf vordefinierten Zeitplänen oder aufgrund bestimmter Ereignisse automatisch auszuführen. Diese Ereignisse können beispielsweise das Eintreffen neuer Daten in einer Tabelle, das Abschließen einer Datenpipeline oder das Erreichen eines bestimmten Zeitpunkts sein. Die Funktion bietet somit eine Möglichkeit, komplexe Datenpipelines zu automatisieren und sicherzustellen, dass wichtige Abfragen zur richtigen Zeit ausgeführt werden. So weit so gut.
Use Case
Der Ausgangspunkt für das Entwickeln unseres eigenen Lösungsansatzes war, dass das Tracking Setup eines Kunden aus verschiedenen Teilbereichen bestand und jeder dieser Bereiche in ein separates Google Cloud Platform (GCP) Projekt mündete. Zudem gab es noch ein GCP Projekt, das alle Daten der sogenannten „Sub-Bereiche“ bündeln sollte und daraus u.a. Dashboards für eine Gesamtansicht erstellt werden sollten.
Zuvor wurden die Queries standardmäßig einmal täglich zu einer bestimmten Zeit ausgeführt. Das Problem: Google „scheduled“ die Queries nicht immer zur gleichen Zeit. Somit ist es bereits öfters vorgekommen, dass die aggregierten „Scheduled Queries“, die für die Gesamt-Dashboards gedacht sind, nicht immer alle Daten enthalten haben, da einige „Scheduled Queries“ für die Sub-Bereiche noch nicht prozessiert waren.
Zweck unserer Lösung ist es, dass das Ausführen der „Scheduled Queries“, die Abhänigkeiten haben (z.b. das vorherige Fertigstellen der „Scheduled Queries“ für die Unterbereiche) nicht mehr zeitgesteuert ist, sondern eventgesteuert. In diesem Fall sollte jeweils „abgewartet werden“ bis alle Abhängigkeiten vorhanden sind und erst dann das entsprechende „Scheduled Query“ starten.
Wie funktioniert unser Lösungsansatz für „Evend Based Scheduled Queries“ genau?
Alle Projekte schreiben die „Log-Events“ ihrer isolierten Google Analytics Dataset Updates in eine sogenannte „Sink“. Eine „Sink „ist das Ziel, wohin Daten nach der Verarbeitung oder Abfrage verschoben werden, um sie zu speichern oder weiter zu analysieren. Das Ziel unserer „Sink“ ist ein „Cloud Storage Bucket“, das sich im Zielprojekt befindet und in welches Daten exportiert werden. Für diesen „Storage Bucket“ wird eine Cloud-Funktion erstellt, die, durch in dem Bucket erstellte Objekte, getriggert wird. Die Cloud-Funktion prüft dann mithilfe eines JSON (JavaScript Object Notation) Files, ob der Ressourcenname, der diese Funktion ausgelöst hat, mehrere Abhängigkeiten hat und wenn dem so ist prüft sie analog, ob alle Abhängigkeiten vorhanden sind. Wenn alle Abhängigkeiten vorhanden sind, werden die entsprechenden geplanten Abfragen für die Dashboards automatisch gestartet und die durchgeführten „Scheduled Queries“ in eine Datei in einem „Storage Bucket“ geschrieben, um somit ein erneutes Ausführen zu verhindern. Wenn dem nicht so ist, wird die Funktion an der Stelle beendet. Die folgende Abbildung verdeutlicht den Prozess.
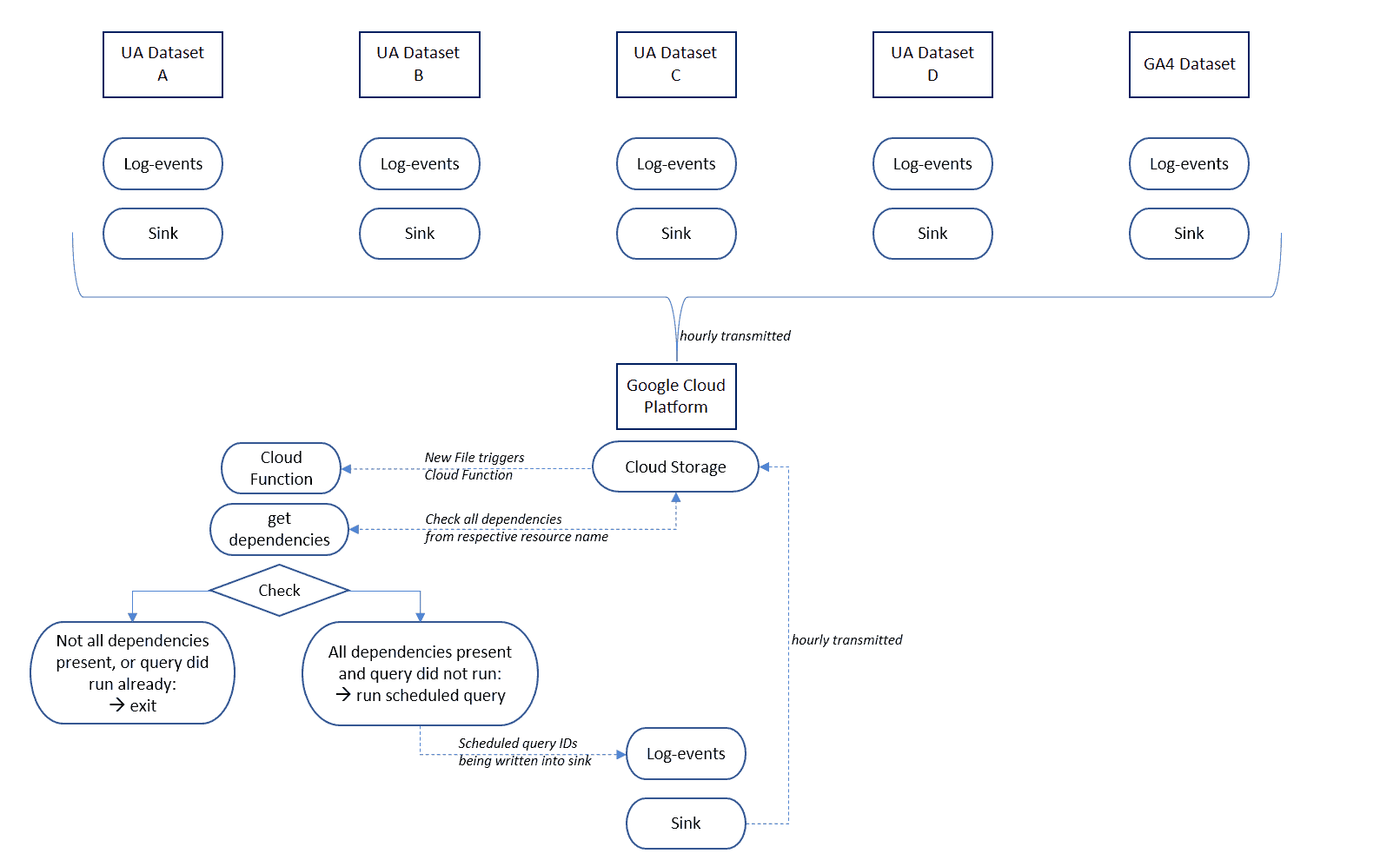
Die einzige Einschränkung ist, dass die Log-Events nicht in Echtzeit, sondern nur stündlich in den Cloud Storage geschrieben werden.
Ihr seid auf der Suche nach der perfekten, automatisierten Lösung für eure individuellen BigQuery Abfragen? Unsere erfahreneren Data Engineers optimieren und automatisieren Eure individuellen (Analytics) Prozesse und konzipieren mit Euch gemeinsam die für Euch ideale Systemarchitektur: von automatisierten Datenabfragen verschiedener Datenquellen, über das Erstellen von maßgeschneiderten Data Pipelines bis hin zur Bereinigung und Harmonisierung eurer Daten. Sprecht uns an!
Feedback
Wir freuen uns über Feedback und weiteren Austausch zu BigQuery und Best Practices.